

If you’re here, you probably already know what web scraping is. But on the off chance that you just happened to stumble upon this article, let’s start with a quick refresher on web scraping, and then we’ll move on to goquery.
Web Scraping – a quick introduction
Web Scraping is the automated method of extracting human-readable data output from a website. The specific data is gathered and copied into a central local database for later retrieval or analysis. There is a built-in library in the Go language for scraping HTML web pages, but often there are some methods that are used by websites to prevent web scraping – because it could potentially cause a denial-of-service, incur bandwidth costs to yourself or the website provider, overload log files, or otherwise stress computing resources.
However, there are web scraping techniques like DOM parsing, computer vision and NLP to simulate human browsing on web page content.
GoQuery is a library created by Martin Angers and brings a syntax and a set of features similar to jQuery to the https://go.dev/.
jQuery is a fast, small, and feature-rich JavaScript library. It makes things like HTML document traversal and manipulation, event handling, animation, and Ajax much simpler with an easy-to-use API that works across a multitude of browsers.
– jquery
GoQuery makes it easier to parse HTML websites than the default net/html package, using DOM (Document Object Model) parsing.
Recommended Reading: Rest API in Golang
Installing goquery
Let’s download the package using “go get“.
$ go get -u github.com/PuerkitoBio/goquery

A concise manual can be brought up by using the “go doc goquery” command.
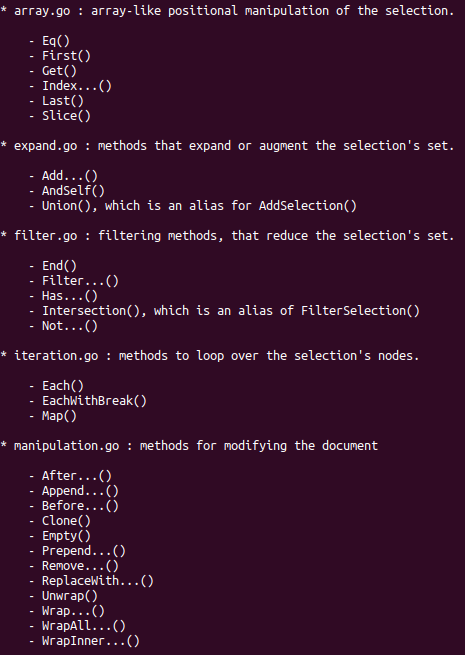
Golang Web Scraping using goquery
Create a new .go document in your preferred IDE or text editor. Mine’s titled “goquery_program.go”, and you may choose to do the same:
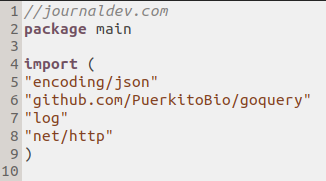
We’ll begin by importing json and goquery, along with ‘log‘ to log any errors. We create a struct called Article with the Title, URL, and Category as metadata of the article.
Within the function main(), dispatch a GET client request to the URL journaldev.com for scraping the html.
res, err := http.Get("http://journaldev.com")
if err != nil {
log.Fatal(err)
}
defer res.Body.Close()
We have already fetched our full html source code from the website. We can dump it to our terminal using the “os” package.
import(
//"fmt"
"os"
"io"
)
func main(){
// the above code
n,err := io.Copy(os.Stdout, response.Body)
if err != nil {
log.Fatal(err)
}
log.Println("Number of bytes copied to STDOUT:", n)
}
This will output the whole html file along with all tags in the terminal. I’m working on Linux Ubuntu 20.04, so the output display may vary with system.
It also gave a secondary print statement along with a notification that the page was optimized by LiteSpeed Cache:
Number of bytes copied to STDOUT: 151402
Now, let’s store this response in a reader file using goquery:
doc, err := goquery.NewDocumentFromReader(res.Body)
if err != nil {
log.Fatal(err)
}
Now we need to use the Find() function, which takes in a tag, and inputs that as an argument into Each(). The Each function is typically used with an argument i int, and the selection for the specified tag. On clicking “inspect” in the JournalDev website, I saw that my content was in <p> tags. So I defined my Find with only the name of the tag:
doc.Find("p").Each(func(i int, s *goquery.Selection) {
// For each item found, get the band and title
fmt.Printf("next")
txt := s.Text()
fmt.Printf("Article %d: %s\n\n",i,txt)
})
- The “fmt” library has been used to print the text.
- The “next” was just to check if the output was being received(like, for debugging) but I think it looks good with the final output.
- The “%d” and “%s” are string format specifiers for Printf.
Web Scraping Example Output
The best thing about coding is the satisfaction when your code outputs exactly what you need, and I think this was to my utmost satisfaction:
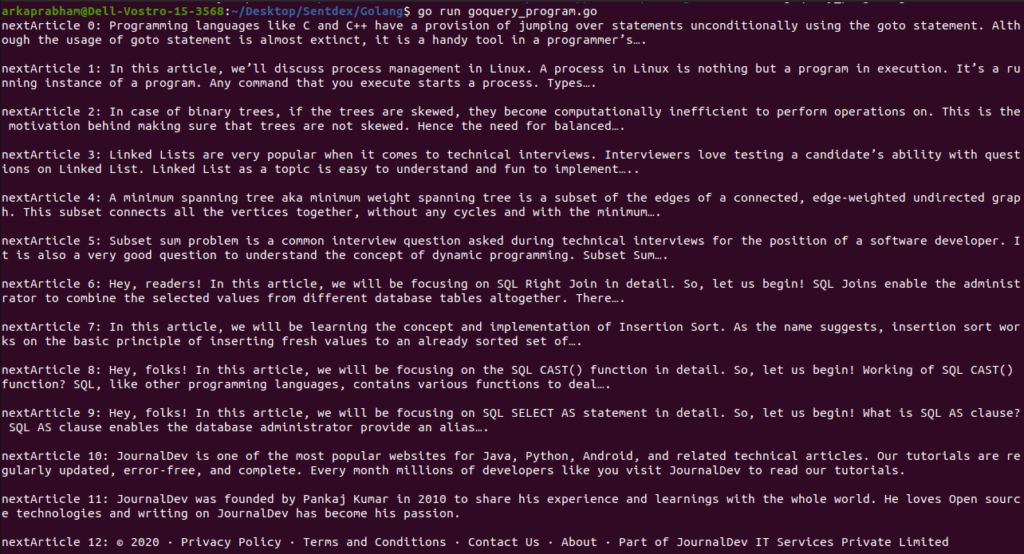
I tried to keep this article as generalised as possible when dealing with websites. This method should work for you no matter what website you’re trying to parse !
With that, I will leave you…until next time.
References
- https://github.com/PuerkitoBio/goquery
- https://www.journaldev.com
- https://api.jquery.com/text/